

Development Journey on Game Decompilation Using AI — Part 3
Let's automate the workflow by building a VS Code extension tailored for decompilation

In the first chapter, I described my attempts to integrate AI into decomp.me. Unfortunately, they weren’t accepted, mainly because the value wasn’t clear and the proposed user experience was clumsy. In hindsight, I understand and agree with that feedback.
Moving into the second chapter, I walked through the decompilation of Kyacchaa. After this job, this idea struck me: instead of shoehorning AI into decomp.me, why not build a VS Code extension?
This new approach offers so much more flexibility. Since the extension will run on the same workspace as the source code, we can pull richer context into the AI prompt, and fully automate the workflows I had been doing manually, such as finding good examples to include in the prompt, and even running an agent mode.
Building a standalone VS Code extension also makes sense from an engineering standpoint. VS Code provides entry points useful for AI-powered extensions, and I already have experience in that ecosystem1.
Introducing Kappa

In this chapter, I’ll share the development journey of Kappa, a VS Code extension tailored for matching decompilation. Fun fact: in Japanese folklore, “kappa” is a mythical frog-like creature, and since the decomp.me icon is also a frog, the name just felt right: short, mystical, and on-brand!
The Kappa's core features are:
🔌 Automated Code Fixes. Plugins to fix automatically and programmatically the errors that AI usually commits.
✨ AI Prompt Builder. Craft high-quality prompts to guide AI in decompiling a function.
🤖 Agent Mode. Let AI iterate automatically until it reaches 100% match for a given function.
🐸 Integration with decomp.me. Seamlessly creating a scratch.
Let's talk about each one.
🔌 Automated Code Fixes
The idea here is inspired from Babel, the JavaScript transpiler known for its modular plugin architecture. Babel lets users modify the abstract syntax tree (AST) through custom plugins, which makes it incredibly flexible for different use cases. “Transpiler” is a compiler that translates from a source to another source, which both sources are high-level languages.
In Kappa, I’ve adopted a similar philosophy: enable a series of AST transformer plugins for C. The goal is to make them easy to create, so that users can craft and share their own project-specific plugins.
Use case: Avoiding Repetitive Tasks
This flexibility matters because every codebase has its own style and rules. For example, in Sonic Advance 3, we can have a plugin to automatically insert offset comments matching the project convention:
typedef struct {
/* 0x00 */ MapEntity *me;
/* 0x04 */ u8 id;
/* 0x05 */ u16 region[2];
/* 0x07 */ Vec2_32 qPos;
} Entity; /* size: 0x0B */Meanwhile, another project might prefer using explicit offset checks like:
typedef struct {
int foo;
int bar;
} MyStruct;
CHECK_OFFSET_X86(MyStruct, foo, 0x00)
CHECK_OFFSET_X86(MyStruct, bar, 0x04)The flexibility lets we have dedicated plugins following the project style guide.
Use case: Fixing Common AI Pitfalls
A particularly useful case for transformer plugins in the context of AI-assisted decompilation is correcting predictable errors. For instance: a frequent problem is related to variable declarations placed mid-block. AI often inserts variable declarations in the middle of a block, which is acceptable in modern C compilers, but invalid under ANSI C, which requires all variables to appear at the block start.
As described in the second chapter, I tried adding a rule on the prompt asking to only declare variables at the beginning of a block, but it hurt the AI's performance, likely because it overloaded the prompt.
So instead, Kappa uses an AST plugin to programmatically lift variable declarations. You can see here how simple is the code for this plugin. Excluding the tests and comments, it's only ~20 lines!
Development
To build the plugin engine, the first step was obtaining an AST from a C code. I started by searching on Google and NPM for existing packages to produce an AST from parsing a C code, but I could not find a reliable one.
Next, I explored how the official C/C++ extension for VS Code works, but is implementations is too complex. Eventually, I came across vscode-clangd, the official VS Code extension for the clangd language server.
This turned out to be a great fit! A language server like clangd offers more than generating an AST from source. It also offers type inference and symbol lookups. These are features are useful for the transformer plugins, and I’ll eventually need them for the AI prompt builder too.
While developing the plugin engine, I built the following plugins besides the Lift Variable Declarations plugin mentioned earlier:
As the plugin count grew, it became clear that automated testing was essential. While setting up the test suite, I decided to go a step further: exposing the test runner to the extension's users.
It's a bet that it might improve the developer experience when creating a new plugin by:
Providing a standardized way to run plugin tests, built-in to the extension.
Each plugin defines its own test spec, making its behaviour easier to understand at a glance.
By baking testability into the plugin engine from the start, I’m aiming to make it as easy as possible for others to contribute new plugins.
Result
After all this work, I was able to achieve a smooth developer experience and three useful plugins. Of course, it needs to be tested in real-world scenarios, by people actively using them while decompiling a codebase. Still, I believe this is a solid first iteration.
Below is a demo showcasing the Lift Variable Declarations plugin:

Next steps
For now, the plugins are tightly coupled with the VS Code extension: they can’t be run independently. While this setup works for the first iterations, there’s potential value in making them standalone.
If this proof of concept proves successful, I have two ideas for the future:
Extract the plugin engine into a CLI tool, so that any C/C++ project can benefit from it.
Integrate it into decomp.me, assuming the team behind it finds the idea compelling (fingers crossed! 🙏)
✨ Prompt Builder
As soon as I finished the work on the AST plugins, I began developing the prompt builder.
One of the most important components of a good prompt is having useful examples. So I started to work on how to identify decompiled functions which can be a good example, then I can attach its C code and assembly.
My first attempt was under the following assumption: If I want to decompile function A, and it calls function X, and I already have function B decompiled, and B also calls X, then B is likely a good example to include in the prompt.
It’s a rough heuristic, but it provides a practical starting point for defining what makes an example "useful." I was doing it manually before when decompiling Marun and Kyacchaa, then it should be good enough for now.
In short, the current goal of the prompt builder is to automatically identify candidates for C functions to include as examples in the AI prompt, following the heuristic described above.
Analysing the Codebase
Initially, I planned to use clangd to locate where specific symbols (e.g., function names) were used across the codebase. This capability was one of the main reasons I chose to integrate clangd while developing the transformer plugins.
Unfortunately, I discovered a major limitation only after investing time in the integration: clangd doesn’t support symbol search in files that aren’t currently open. While it technically exposes the API for finding symbol references, it’s not as smart as I had assumed. Realizing this late in the process was frustrating, and in hindsight, I should have run more thorough tests up front.
After that setback, I started exploring alternative approaches, including using grep to search the codebase manually. While browsing NPM for anything that could help, I luckily stumbled upon an excellent tool: ast-grep. It supports C, runs via WebAssembly, and, most importantly, it works seamlessly within VS Code.
It offers an incredibly straightforward API for querying AST nodes based on custom rules. For example, if you want to find all calls to foo within functions, the rule is defined as:
rule:
kind: identifier
regex: ^foo$
inside:
kind: call_expressionBesides YAML, it also supports a JSON, which integrates directly with its JavaScript API. You can try it out in their playground to see it in action.
Worth to mention that, although ast-grep does support syntax-aware code replacements (kind of like sed, but AST-aware), I don't think it replaces the custom transformer plugins I developed earlier. The key difference is that my plugins can maintain state during transformations. For instance, the Add offset Comments plugin increments a variable to calculate the next field offset, and the Lift Variable Declarations plugin requires analyzing and restructuring blocks of code, something that looks like beyond ast-grep’s pattern-matching capabilities.
That said, ast-grep is a great building block! I’m considering replacing clangd with ast-grep in the future to handle AST generation and make the type inference programmatically. This could simplify the extension’s architecture significantly by eliminating the need for a language server and unifying the logic across both the plugin engine and prompt builder.
For now, though, I'm continuing to use clangd for the plugins and ast-grep for the prompt builder.
Wrapping the First Iteration
After completing the first iteration of the prompt builder, I was able to gather a list of C functions that could serve as examples. Each one includes both the C source and its corresponding assembly. Initially, I retrieved the assembly from Git history, but I later improved this by pulling it directly from the build folder.
I also added a cap on the number of examples returned, to fit within the prompt size limit for Claude Sonnet 4. Also, I'm still experimenting with the ideal threshold. Is it better to include as many relevant examples as possible? Or does including too many overwhelm the model? For now, I’ve settled on including the top 5 candidates.
While testing the prompts, something interesting stood out: Claude mentioned in its response that a specific example matches particularly well with the target assembly:

In addition to the example, the prompt also includes several other key features:
The callers of the target function, including both their C code and its assembly
The C declaration of the target function
The declarations of functions called by the target function
The type definitions used in those declarations
A set of hardcoded rules to guide the AI’s output
And, of course, the target assembly that we want to decompile
The logic for retrieving the declarations and type definitions is similar as described earlier. The system walks through the codebase and uses ast-grep to locate the relevant piece of codes. Once found, the corresponding code is copied into a context variable, which is then passed to the function that writes the final prompt string.
Talking about writing the prompt string, I briefly considered using LangChain, since it offers a built-in prompt templating system. However, I wasn’t convinced it provided enough value to justify adding another dependency, especially one that might tightly couple the project to a specific framework. In the end, I decided to keep things simple and rely on native JS string manipulation, at least for now.
After all this work, I achieved a great matching rate on the test case I’ve been focusing on, decompiling an enemy from Sonic Advance 3, and shared a video demo showcasing the process and results in action:
Finding Better Examples
So far, the flow works like this: the user selects a target assembly function, and the extension walks through the codebase to gather all the necessary context and then builds the prompt on demand. It's lazily.
However, it’s time to flip that flow. Instead of gathering the context when the user asks to build the prompt, we should eagerly generate a structured database containing the codebase’s context. It should be ahead of time. Then, when building the prompt, the extension can simply query this from an in-memory database.
It speeds up the process, but the goal here isn't performance. Instead, it’s about enabling smarter example selection. By indexing all functions in a database, it’ll be easier to pre-compute vector embeddings from the assembly functions, and search in the database the similar functions by using cosine similarity.
Having everything pre-indexed makes it much easier to evolve the algorithm, moving from heuristic-based matching to a semantic similarity approaches.
AI 101: What do you mean by “vectors” and “similarity of cosine”?
An embedding is a way to represent complex data (e.g., texts, images) as a list of numbers, known as a vector. These vectors capture important features of the data in a format that a machine learning model can understand.
We use a specialized AI model that transforms the complex data into a vector. This process is called embedding.
To compare how similar two pieces of data are, we often use cosine similarity. This method looks at the angle between two vectors, rather than their length. The idea is that if two vectors point in the same direction, they represent similar information, even if their magnitudes (sizes) are different.
In simple terms, cosine similarity helps AI understand how alike two things are, based on the direction their vectors point.
To support this new approach, I integrated RxDB into the extension. It’s a local-first NoSQL database that fits perfectly with the use case. It supports MongoDB-like queries and can run entirely in-memory, enabling fast lookups across all indexed functions.
Once the database was populated with all C and assembly functions from the codebase, I began working on computing the vector embeddings for each assembly function and storing the results in the database.
I began implementing this feature by following a tutorial from the RxDB docs. As suggested there, I initially tried to use a model from Hugging Face to generate embeddings for the assembly functions. However, since the model used in the doc isn't for code, I searched a bit more, and I came across a recommendation in Anthropic’s documentation pointing to Voyage AI. Since my primary goal is to craft prompts for Claude, and Voyage AI offers a model tailored for coding (voyage-code-3) it made more sense to use it.
Voyage AI provides an HTTP API for generating vector embeddings. Thus, it doesn't run locally. While the API itself is quite responsive, the overall embedding process still takes about 2–3 minutes on Sonic Advance 3, since I have to process the functions in batches of 40 per request to stay within the API limits.
With that done, I finally built a vector database for every function in SA3, and I had a semantic searcher to select good examples!
I ran some initial tests, and it improved the quality for decompiling the code, and it's more predicable. Before, depending on the examples randomly selected, the result would be good or bad, now, it's more stable and with good results.
Scatter Plot
While working on the embedding feature, I took a little side quest to visualize the data with a scatter plot.
I used umap-js to reduce the high-dimensional vectors into 2D space, and then rendered the chart using chart.js.
You can see it in action below:
Explaining the chart:
Each node is a function, and functions with similar vector data (i.e., assembly) are placed closer together
Pink nodes represent functions that have already been decompiled
White nodes are functions that haven't been decompiled yet
Blue nodes are functions present in the selected folder or module
Pink node has the highest z-index
I think the results are promising!
If the functions were too scattered, finding good examples would be harder, and the result from LLM would be worse. But based on this plot, it looks like that, most of the time, we have many nearby functions.
It's great because when decompiling a function using LLM, it'll probably have neighbours offering good examples. For the big clusters with no examples yet, I think that we can decompile a few of them manually, and use LLM later to handle the rest in the same cluster.
I know we have some isolated and small clusters (e.g., at (0, 10) and at (3, -6)), but in most cases there are big clusters.
Of course, this is still an assumption, but I’m excited to test more in the next chapters. That said, I’m feeling confident that the results will be fantastic!
BSim?
When I shared the scatter plot on Twitter, a friend replied to me suggesting that I try BSim instead of voyage-code-3. BSim is a feature from Ghidra, specifically designed for generating feature vectors from assembly functions.
BSim takes a fundamentally different approach compared to voyage-code-3. Instead of using a neural embedding model, BSim builds feature vectors directly from Ghidra’s decompiler output. The decompiled code is first split into small chunks, and each chunk is assigned a locality-sensitive hash. To compare two functions, BSim looks at their hash vectors and computes a dot product similarity between them. You can find more details in the official documentation and in the source code.
I spent a few nights diving into BSim, since it looks quite promising. But ultimately, I decided to hold off for now. Voyage is already performing well enough for my current needs, and integrating Ghidra on Kappa would require a lot of plumbing.
Moreover, although Ghidra is highly scriptable, I couldn't find a quick way to implement a "find all similar functions for X" for Kappa using BSim. The UI offers this feature, but the scripting support seems limited. I found an example for 1-to-1 comparisons, but nothing readily for searches in the whole codebase.
Finally, while not a blocker, I’m unsure how I’d go about plotting a scatter chart using BSim’s feature vectors, since they’re based on locality-sensitive hashes rather than numerical embeddings.
Next Steps
Using Voyage was a quick win. It's easy to integrate and works well out of the box. However, it does introduce some friction in the user experience: users need to provide an API key with at least Tier 1 access, which means paying $5. That said, the free token quota is way more than enough to cover an entire project like Sonic Advance 3, so users likely won’t need to pay more.
A next step would be supporting for running an embedding model locally, removing the dependency on external APIs.
It’s also worth mentioning that Ethan, the creator of decomp.me, is working on a tool called Coddog: a tooling to identify duplicate functions and portions of functions among one or more binaries. Once it becomes more stable, it could be useful for enriching the prompt with more examples.
Beyond that, I still need to set up a testing environment for prompts to evaluate some fine adjustments. For example, I don’t yet know the ideal similarity threshold when selecting example functions, or how many examples should actually be included in a prompt. I also want to measure how well the hardcoded rules are performing, whether they’re helping, if some should be removed, or if additional ones might improve results.
🤖 Agentic Mode
With all the foundation in place, it's time to dive into the most exciting part of this chapter: Agentic Mode for decompilation!
Prompt Design
In the previous section, we made a prompt builder focused on the ask mode. The next step is extending it to support the agent mode, where the AI operates autonomously to refine and improve its output until reaching a termination condition.
Thus, we need to include some key components on the agent mode prompt:
Verification Loop
Success Criteria
Termination Condition
It was relatively straightforward. I started with a few basic rules, then asked Claude to improve them. After a few rounds of testing and refinement using VS Code Copilot, I arrived at a set of rules that worked well in practice.
Integrating with an Assembly Differ
While testing the prompt, I realized the verification loop needed to be more robust. Although Copilot can read the .asm files directly to analyse the differences between the current assembly and the target one, expecting it to do that reliably is too much. It needs proper tooling support.
I started by looking into asm-differ, which was the only differ tool for decompilation I knew at the time. It’s written in Python and requires a few configuration steps to get going.
To make it work with Sonic Advance 3, I had to fix an issue in the project’s Makefile. After a few hours of setup and debugging, I finally got asm-differ running with support for debug symbols.
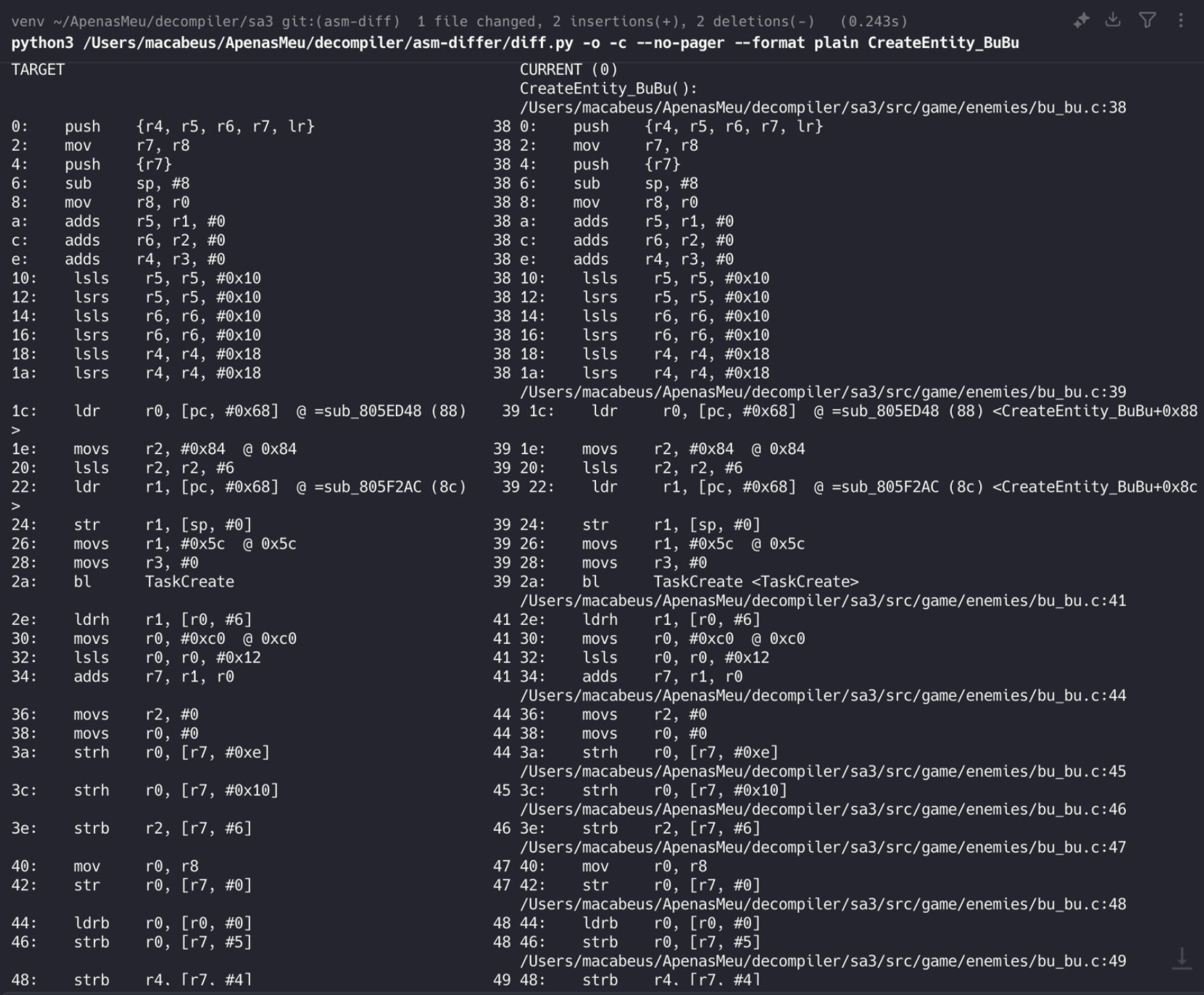
Next, I updated the prompt by adding a rule telling Copilot to run asm-differ when the checksum fails, so it can identify the remaining gaps.
Although it worked, I ran into two main issues:
The output is a plain table with inline references to the source code. While LLMs might understand it, they'd perform better with a Markdown format that avoids tables, highlights the differing lines, and inlines the relevant source code.
Also, asm-differ wasn’t correctly detecting the end of the function. It compared everything from the target function onward, adding a lot of noise.
Since I couldn’t resolve that second issue, I asked for help on the decomp.me Discord server. There, a user asked why I was using asm-differ instead of objdiff. The truth? I just didn’t know about objdiff!
So, I decided to give objdiff a try. It's written in Rust and has a WebAssembly-based NPM package, which means I can bundle it into the VS Code extension and easily call the objdiff functions from TypeScript. It’ll help to format the output in a way that’s optimized for LLM. Also, there's even an official VS Code extension for objdiff, which I can study the source code.
The setup for objdiff was also much simpler. I can use the CLI to compare object files directly:
./objdiff diff -1 build/gba/sa3/src/game/bu_bu.o \
-2 expected/build/gba/sa3/src/game/enemy_bu_bu.o \
CreateEntity_BuBuFor accurate results on objects for GBA, I had to include specific flags. The final command is:
./objdiff diff -c arm.archVersion=v4t \
-c functionRelocDiffs=none \
-1 build/gba/sa3/src/game/bu_bu.o \
-2 expected/build/gba/sa3/src/game/enemy_bu_bu.o \
CreateEntity_BuBuUnlike asm-differ, objdiff correctly scopes the functions, avoiding noise from unrelated code.
After getting objdiff working via the CLI, I began integrating it into my extension. That’s when I hit a limitation: the Wasm version of objdiff doesn’t work on VS Code’s host environment. The official objdiff extension didn't have this issue because it runs from a webview.
VS Code Extension 101: What do you mean by “host” and “webview”?
There are two distinct environments on a VS Code extension: the host and the webview.
The host is where your extension starts. It has full access to the VS Code API and handles tasks like file access, commands, and workspace operations.
The webview, on the other hand, is used to display custom UI inside VS Code. It runs in a separate context, essentially like an isolated browser environment. It can use standard browser APIs, but cannot access the VS Code API directly.
Typically, the host and webview communicate via a message-passing system.
According to the VS Code docs, the host environment has known limitations with Wasm, and extensions targeting it should be built using wit2ts to avoid hitting these limitations. Currently, objdiff uses WASI Preview 2, which isn't compatible out of the box on VS Code host side.
I tried wrapping objdiff inside a webview, but it added too much complexity and a bad user experience. So, I tasked VS Code Copilot to search for a workaround while I explored in parallel building objdiff with wit2ts.
To be frank, I didn't expect Copilot to find a suitable solution, but, to my surprise, Copilot actually found a hacky but effective workaround: by mocking fetch and WebAssembly.compileStreaming, it was able to run objdiff directly on the host thread without a webview!
It isn't the cleanest solution, but it works well for now, so I’ve decided to move forward with it.
As the next step, I made objdiff output a Markdown content. It’s worth noting that Copilot was a big help here. I added the official objdiff VS Code extension repo to the context on the chat, and it generated most of the code needed to produce a good Markdown output. Of course, I had to spend a few hours cleaning up the code generated by Copilot, but having a working starting point made the process much easier.
I also integrated objdiff with the chat by exposing it through the Language Model Tool API. This API is simple and easy to work with. One great advantage from this feature is its flexibility: although I initially designed it for use in agent mode, it also works in ask mode. For example, users can directly call objdiff and ask to explain a mismatch in the diff.
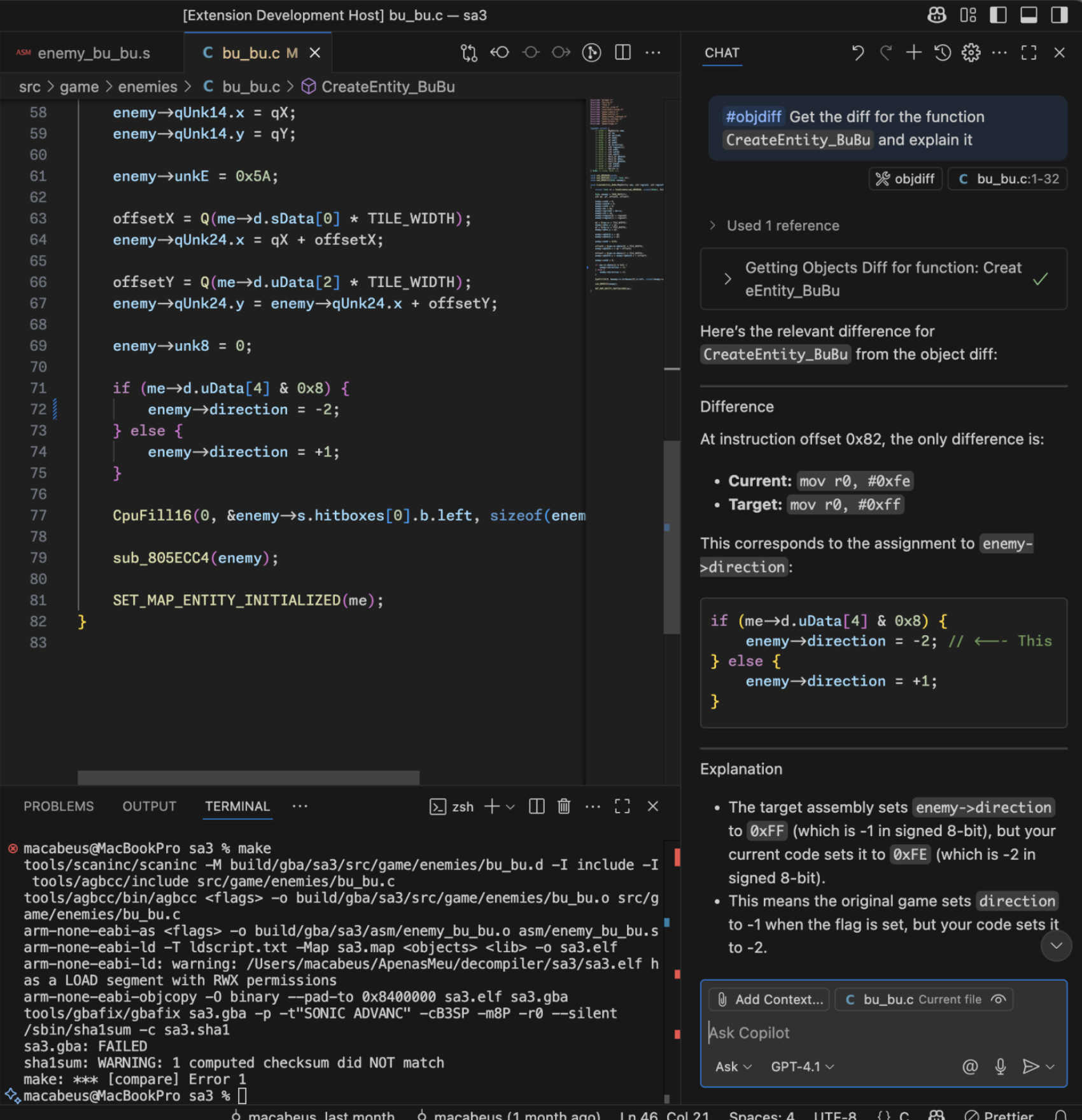
With all this in place, I finally had a smooth and fully working version of agentic mode up and running! It was incredibly satisfying to see it in action, behaving as a self-correcting agent for decompilation.
Below is a demo showcasing the agent in action, decompiling a function from an enemy module in SA3. In this example, while working on the target function, Copilot noticed a struct definition was incorrect and fixed it. However, since the same struct was also used in another function, that function started to mismatch. Copilot then identified and fixed the second function as well, ensuring the entire module matches. This follow-up action is triggered by a note at the end of the objdiff output, which Copilot uses to identify the mismatch and determine the next step.
Next steps
Unfortunately, while asm-differ correctly maps C code lines to their corresponding assembly instructions using debug symbols, I haven’t been able to achieve the same with objdiff. This seems to be a limitation from objdiff. From my testing, Claude Sonnet 4 is smart enough to infer the correct mappings, but having explicit symbol information would still be valuable, especially for more complex functions or different compilers.
Another improvement would be to introduce more Language Model Tools. For instance, allowing to query the local database from the chat requesting examples might be useful for both agent and ask modes.
Lastly, it would be great to remove the workarounds for fetch and WebAssembly.compileStreaming that were used to get objdiff running in the VS Code host thread.
🐸 Integration with decomp.me
To wrap things up with a bang, let's integrate Kappa with decomp.me. It’ll be similar to what we have with objdiff, allowing users to quickly create a scratch on decomp.me.
I added a third code lens that appears above each assembly function. When clicked, it opens a new scratch on decomp.me for the target function.

Well… I think three code lenses is the limit for keeping things clean. If I need to add more actions in the future, I’ll likely need to explore a different approach for triggering them from an assembly function.
The initial setup was straightforward. I asked Copilot to look into how objdiff integrates with decomp.me and read its source code. That gave me a good starting point to implement scratch creation from Kappa.
However, I had to make several adjustments to improve the user experience and configurations, that the generated code by Copilot didn’t fully handle.
I wanted users to configure once the platform, context file, compiler, and optionally a preset. These preferences are saved in the workspace so they can be reused later. Importantly, the decomp.me configuration is optional and only required when the user explicitly tries to create a scratch.
At first, I introduced a new config file named kappa-config.json. But the next day, a guy pointed out on the decomp.me Discord that there's already a standard config format for decompilation tooling. That immediately clicked with me: I had been wanting something like that all along.
So I replaced kappa-config.json with decomp.yaml and updated the schema to match the emerging standard.
From what I can tell, Kappa is now the third project adopting this format. Hopefully, this doesn't become yet another case like the xkcd comic about standards. That said, I'm happy to give it a shot and help consolidate it.
As soon as the basic functionality was working, I enhanced it by automatically including the type definitions used in the target function in the initial scratch code. Since I was already gathering this information for the prompt builder, it was straightforward to reuse that logic for this new feature.
Next steps
Right now, we can only create a scratch from an assembly function. It would be helpful to also support creating a scratch from a C function. For example, a user may have already started decompiling a function locally, removed the assembly code, and later decide to offload the work to decomp.me if they hit a wall.
A next improvement would be to integrate it with VS Code Copilot. If the agent gives up on reaching a full match, it could suggest creating a scratch.
Lastly, a useful addition would be a sync feature. If the code on decomp.me changes, the user might want to update their local version with the one from decomp.me.
Conclusion
Wow, this chapter was long! I spent 10 weeks coding and writing it (started back on May 22nd!). If you’ve made it this far, thank you for reading!
Reaching a successful match for a function in Sonic Advance 3 using the agent mode was a big milestone. But of course, we’re still a long way from the ultimate goal: fully decompiling a game using only AI.
To move forward, the next essential step is measuring effectiveness.
That means setting up an evaluation environment to assess how well prompts and models perform. And it’s not just about matching: we also care about code quality. While I was testing the agent, I’ve seen it matching the function successfully but producing a low-quality code (e.g., using unnecessary pointer arithmetic or ignoring existing struct definitions).
I might give a try on vscode-ai-toolkit, or maybe building a custom evaluation environment on top of a framework.
So, see you in the next chapter, where we’ll dive into evaluating prompt effectiveness for decompilation!
I've developed two extensions so far: vscode-fluent and Frontier.